In this tutorial, I’m going to address some things that a lot of people don’t know. How to resize an image in Photoshop and keep the best quality. Here is what I’m going to cover.
I am using Photoshop CC, however the basics apply to every version of Photoshop, although the resize dialog box and options are a bit newer in CC. Don’t forget to check out the video for a full walk through and look at the written info below for more details or specific topics.
How to resize an image in Photoshop for best quality. Best settings for resizing, enlargements and reductions of image sizes in Photoshop. Ultimate guide to resizing
First of all, I created a test image. This contains, fine lines, thicker text, fine curved lines, gradients and an image so you can see the results on different types of images. Grab the image right here to test for yourself. (right click and save the image below).

It’s very easy to resize an image. Choose Image>Image Size
You will see this dialog box.
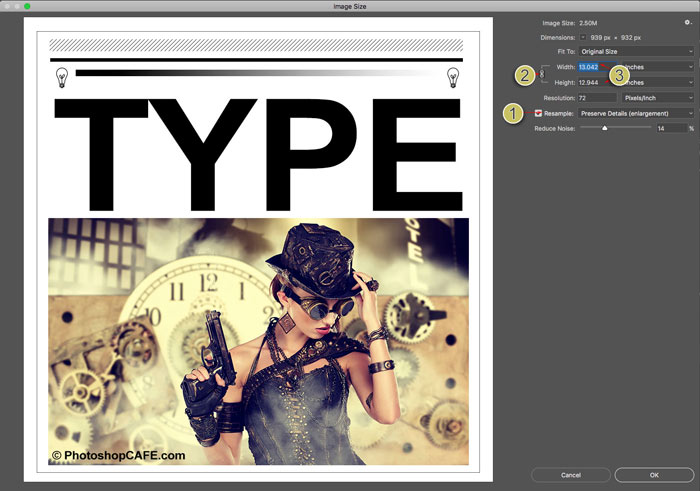
That’s all you need to do to resize your images. Keep reading for more details on how to get the best results if you are ready for that info.
Without overly complicating things, the resolution is what you see on screen or in print. On screen you see pixels of light and in print you see dots of ink. This is where the terms DPI (dots per inch) and PPI (pixels per inch) come from. In an over simplification, you can think of them as the same thing, however dots refer to print and pixels are a digital display. Many people mistakingly talk about DPI on screen, this is incorrect, but now you will know what they mean. DPI and PPI are both a way to describe resolution.
You have heard the terms hi-resoluton, or low-resolution, or low-res. This means how dense are the pixels (or dots). More density = more resolution, or detail. If there is not enough resolution (image isn’t big enough) then you will see a noticeable softness to the image, or even jaggies (also called pixelization). Too much resolution, won’t affect the image display quality, you will just have an unnecessarily large file. So let’s find the best resolution for your needs.

The goal is to keep the quality as close to the original as possible and this article will show to how to do that. This is one of the big things that separate the pros from the amateurs, the quality of the final images.
Every screen has a native resolution, maybe its 750 x 1334 pixels or 326 ppi as the iphone retina. 326 refers to 326 square pixels fit into 1 square inch of the display to perfectly match the screen size. But a better way to measure screen resolution is with overall pixels.
Print is measured in dots per inch (DPI) (LPI Lines per inch or line screen is used in commercial printing). If you have more dots in a square inch, you will have more resolution or detail in your print. Typical print resolution is 300dpi (some inkjet printers print better at 360 or 240 for example, look at your specs). This means that there are 300 dots of ink per square inch or printed material. If your image is less, it will look soft, if its larger, there is no benefit as a printer can’t print beyond its maximum resolution. Ok, how to tell if it’s the right size?
You will now see that a 939 x 932 pixel image can print at 3.13 x 3.1 inches and look nice and sharp at 300ppi/300dpi. If you need to it print larger you either need to select a larger image or scale the image up (resample).

The problem with sampling up (enlarging) is that you will lose image quality. The larger you make it, the more quality you will lose. If you need to scale the image down (reduce) then the quality loss isn’t so much as issue, although you may need to sharpen an image if you shrink it too much (more about that soon).
If someone asks for an image of a certain size, just saying “4×6 inches” or “at 300dpi” doesn’t give you enough information. Sometimes people even go as far as to say “300 dpi at 12Mb,” this doesn’t help either because the file size doesn’t really have bearing on the physical size of an image because file compression and file type all effect this. What you need to know id one of 2 things, either
When you change the size of the image, Photoshop has to recreate the pixels. Photoshop needs to know how to jam the pixels together and which ones to throw away when you scale down. It also needs to know how to create pixels when scaling up. This process is called resampling. When you scale an image even by a single pixel, the entire image is resampled or rewritten. This is why creating the image at the correct size in the first place is great. However, don’t fear, Photoshop does a really great job of resampling and many times you will never be able to see the difference in quality.
In order to resample, Photoshop has to do some math to know how to recreate pixels. This math is called interpolation (in-terpol-ation). Interpolation is important because certain types of interpolation will give you better results for different types of images. I’m going to attempt to keep this as non-technical in simple language and guide you to the best options. There were originally 3 types of interpolation in Photoshop (here is a non-scientific way for you to look at them).
Typically bi-linear is best for line art and simple graphics, where are bi-cubic is best for photos and graphics containing gradients, but wait, it doesn’t stop here.
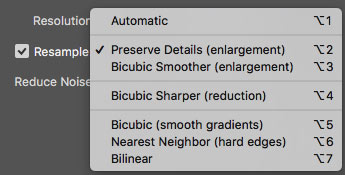
Adobe added 2 more types of Bicubic (In Photoshop CS3). They added:
(See what features were added in which versions of Photoshop in our free superguides)
There are 2 more options what are they?
Automatic (Photoshop CS6) , it selects Bicubic Smoother (CS6) / Preserve Details (CC) when enlarging and it chooses BiCubic Sharpener when reducing images. Automatic is easiest most of the time, but keep reading because it might not best the best option all the time.
There is a “secret squirrel handshake” for experienced Photoshop users “in the know.” This secret is often credited to Fred Miranda, for discovering the stair step interpolation. It works like this, when you enlarge or reduce an image, rather than just jump to the final amount, scale it up or down at 10% at a time. You will see a marked improvement in your image sharpness and final quality IF you are using CS6 or the older interpolation algorithms.
However, on testing I have found that Preserve Details produces the same result as stair step and I hazard a guess that some of that is built into the newest algorithm. This was one of the unsung heroes in the first release of Photoshop CC.
Ok, this is where the rubber hits the road and it’s a good time for you to open the test image into Photoshop and test for yourself. You can also see me test it on the video above.
I have found for upscaling that Preserve Details works really well for for many images, especially line art and graphics images (although for simple line art, sometimes bi-linear yields better results). However, sometimes for photographs bi-linear smoother can produce a more natural (although softer) results which has less halos and artifacts. You can always apply some sharpening to the result. The results depend on how much you are scaling up the image and also how detailed the image is vs large gradient areas such as skies in photos. So, don’t just reach for auto. Try a couple of variations to see if you can coax better results out of Photoshop, sometimes you can.
Check out this article I made that explains resolution. Its a simple explanation of why describing a images as 300DPI, 72dpi etc doesn’t mean anything.
Ok, if you are still reading you are either a bit more advanced, or hungry to learn all you can. When you are scaling up or down images here are some tips to keep in mind.
Thanks for checking out this tutorial / article. Don’t forget to subscribe to our mailing list (on the top right of the toolbar) to be informed whenever I post a new tutorial. I usually do a tutorial each week which has BOTH a written and a video component to it for your learning pleasure.
If you are really wanting to get a good grasp of all the goodness in Photoshop, don’t waste time with tons of disjointed tutorials from “experts” that overlap and sometimes disagree with each other. Your time is YOUR most valuable asset. This is why I put together a comprehensive Photoshop course that teaches you A-Z all in 1 place. I first started this in Photoshop 5 and have re-recodred this course 10 times over the past 17 years, perfecting it each time. I believe its the best way to learn Photoshop and thousands of people would agree with me. Have a look at Photoshop CC forDigital Photographers (It’s really for anyone working with images in Photoshop) Over 100 lessons and 13 hours of valuable inside information. It’s plain-english so anyone can understand it as well as the real-world techniques used by experienced pros. All the lesson files are included so you can follow along with me, step by step. Full 60 money back. Grab in the instant Download or DVD right now.
Thanks guys!
Check out more tutorials on PhotoshopCAFE!
Colin

This site uses Akismet to reduce spam. Learn how your comment data is processed.

How to control color with Curves in Photoshop, easier and more powerful than you imagine...

How to use the new features in the frame tool in Photoshop. ...











I never knew any of this! I recall some tutorial saying something about Bicubic being a good choice in many instances, but, that was it! LOL Thank you very much!
Su
I apologize that a few of the comments have been deleted. Because of some technical problems I had to reupload this page.. Feel free to repost
Nice
all sites postig topics about make an image larger, what about it making it smaller without losing quality, i still looking for a good video or a articl since hours but not luck yet -__-
Bicubic sharper for reducing
what I am trying to do is make the image of a lady smaller before I place it on the new back round, so it looks like it fits the scene, Im not interested in reducing the size of the finished new image on new back round
any thoughts on that subject
I love your vid “how to make a composite ”
but my question if I wanted the soccer player to be smaller to fit the back round
HOW
THANK YOU IN ADVANCE
Nich Mast
Press Ctrl+T and drag the corner to change the size
The lesson is an eye opening for the beginner like me. Thanks.
I had a query we are now living in responsive era, so the images that we use in web are scale up for big screens and the same images are scale down on small device so there an idle option for such situations BiCubic Smoother, Bicubic sharper,etc.
When designing you make the image at the largest size it will be needed, the browser will resize it from there.
Thanks for explaining the resolution, in such detail but, I got stuck on one line “If you need to scale the image down (reduce) then the quality loss isn’t so much as issue, although you may need to sharpen an image if you shrink it too much (more about that soon).”I am waiting More about that soon 🙂
Its covered in the resizing an Image section
Bicubic sharper: Sharpens to bring back lost details while reducing a file
Suppose we have to resize single image which has both (small) text and picture and the image is scale down on small device and scale up on big device, so is resample the idle option, if yes then under resample which option to consider Bicubic sharper or Bicubic smoother or Preserve detail ?
Thanks but i am still facing issue, i created a logo of 1187X360 but my theme have a logo space for 260X80, when i save for web devices is blur.. i am looking for a solution.
regards
MJ
My concern is trying to save a panorama of 8 or more images combined, which makes the file QUITE LARGE (+4Gb), sometimes PS won’t even let me save the file. What’s the best saving method would you suggest for these instances? Thanks in advance for your reply!
Save these as PSB format, they can handle larger files
Thank you for the help.
I am entering a photograph into my first competitive exhibition. The image is a composite of 16 individual images stitched together. The combined image dimensions are: 11,124 x 18,719 pixels. I have two tasks to accomplish and I would appreciate your guidance. 1. To submit the image for jury, it needs to be a maximum of 3mb and the shortest dimension must be at least 1200 pixels. They will print the image on paper (don’t know what kind of paper or the dpi printer setting) for judging. I am guessing I should resize the image to maximize its quality but your comments about the image becoming soft suggests for such a large resizing the sharpening needs could be significant. Do you have any suggestions to maximize the quality of this image file beyond the guidance you have provided? 2. If my image is selected, I will need to print for display at the gallery. My original dimensions would theoretically allow an image of 36″ x 54″ at 300 ppi. Given the image is stitched do you know if there is any risk of the boundaries being visible if printed at the max? As a stitched image, would I be wise to engage in some image reduction to maximize the crispness of the composition? Any guidance would be greatly appreciated.
If its stitched properly, there shouldn’t be any visible seams.
i want to create a tarpaulin that have a size 9 height 30 width whats is the best resolution?
I would ask the printer who is going to print it, what their specs are, they can vary widely, deepening on materials, coating, type of printing etc.
Hello i’m working on ads so i made one artwork size 1080×1080 and i have to resize this same to more 86 different sizes like example 200×100, 300×250, 160×600 and more so i’m looking for easy way to do it because now im making all from beginning every each size theres any way i can do quick without making from the scratch. thank you for your help in advance.
use actions
I’m doing a banner for the front of a counter at one of our facilities, and the dimensions are 134″x58″ (WxH), which is what I set the image size as when I started the project. Halfway through the project though, I’m getting pretty annoyed with how much the massive file seems to be slowing down my top of the line Macbook Pro (purchased in 2017). I have never heard the fan run on this thing until now.
I am wondering if I make my layers smart objects, then resize the image down to a more manageable file size, will I then be able to enlarge it back up once it is ready to go to the printer without losing quality? I feel like this should work, especially if I make the current, edited layers smart objects, but kind of want to confirm before I waste 5 hours of work…
Make a copy and test it, but you shouldn’t lose anything if you are in smart objects. But test it
Hi Colin, I have an image save to a PNG and the quality looks great. When the web developer resizes it smaller to fit the space provided in our website, the image quality becomes really poor. Is there a way we can keep the quality high?
your freelancer is probably over compressing the image. Maybe give it to them in the size that’s needed for the final
I wish I would have found your informative website sooner! I have read so many piece meal tutorials and I just get more confused. Such as one recommendation for print was to only use 600 DPI for printing any photograph! I never heard of this and the way the person described that 600 was the best and using anything else you were basically a loser in the photography field. Your explanations are clear and easy to follow. Thank you. I will be following and looking forward to some of your courses. For certain situations I just need a refresher on the process.
Nice article. From my experience in print production, I have found that if you first determine the proper monitor resolution and set that in Photoshop (generally it shouldn’t be set at 72dpi) viewing your image at print size is a bit more accurate as to what you will end up with (since no one will ever see your image at 100% monitor size). So for example, I have an Apple Thunderbolt monitor which has a display resolution of 2560×1440. If you measure the actual width of the screen (in this case 23.4in) and divide 2560 by that number you get a screen resolution of 109. You then enter this into the screen resolution box under Units and Rulers in Photoshop preferences. Then when you choose view print size, your image should measure exactly to its final print size. In my opinion this is a more accurate way to determine if your upsampling will look ok as a 100% monitor view shows way more detail than the human eye can see at the size the image will be printed.
hello
I am reducing icon size 24×24 to 16×16 my file is pixcelate what should i do to fix this trubble
Use the downsample option
Hi,
I’m exctracting artwork from PSD/PSB files. Sometimes the size of file gets too high, say 48mb for a 5000×3500 pixles jpg. I need to lower the image size to 10mb in same resolution (5000×3500) while keeping images quality. And setting file on Image Option even on smallest and lowest quality (0/1) when saving it won’t decrease the size and it’s still over 40mb.
Hi Colin
Great column!
What is the max size (%) you should scale up an image before interpolation no longer helps with resolution.
I’ve always set a 400% limit.
Thanks!
I’m reluctant to put a number on it because it varys from image to image.
what is resolution?
Hi, I’m trying to resize an image to fit the banner of a website. The dimensions are 1920×460, so understandably the image is stretching to fit the dimensions. Is there any way to hide the stretching? Or is it just an unfortunate side effect? Thanks in advance
You could pad the image with a solid color or repeating pattern and set the image to absolute rather than relative sizing. Don’t ask me how to do that though, google the CSS 😉
Hi Colin
Thank you for an informative article. I’m trying to resize images to use on a HD monitor, like you’ve mentioned:
“For example many monitors (HD) are 1920 pixels across by 1080 pixels high. 1920×1080” with these exact sizes or the short size may be less than 1080. But what I find is that when it resize automatically the small size is always bigger than 1080 and when I resize the small size to fit 1080, the image is distorted. How do I prevent the distortion and keep to the “rule of 1920×1080 (or less)?
Thank you
Also to mention when I resize my images to 1620×1080 it is perfect, no distortion.
Hi Colin,
I’ve been a fan since taking your online courses for Photoshop and Illustrator. I need to figure out the resolution when I resize images for use in Pan & Zoom effects. In the SD days when screens were 72 dpi it wasn’t a problem, but now, I am often given small digital downloads of images to work with and the project is never less than 1920×1080. I’ve been eyeballing at 100% but would like some guidelines from a pro. Thanks!
Thanks for the nice article about scaling up/down pictures. Unfortunately, you’ve got the math of the resolution part totally wrong. E.g. 300dpi is definitely not 300 dots per square inch but 300 pixels per (linear) inch. For square inch it is 300×300=90000 dots per square.
Hi Colin:
Well described. However, what I still have difficulty understanding is how to size images for use on my website. Primarily, I think, because it depends on the resolution of not only my screen but also in the real world where everyone views my site on different devices with different resolutions. How do I resize images ie. crop to fit a given space – full frame – when I don’t know what the size of that space / container is?
BTW, we’ve long used 72 ppi as the benchmark for resizing images for viewing online. However, some time ago I read that most monitors today are more likely 95. What do you suggest?
Another great tutorial Colin.
Do you use photoshop to resample a image up or do you use another program and is there a better alternative to photoshop? I would like to know what you think.
I use Photoshop. Alienskin blow up was pretty good in the day along with Genuine Fractals, I don’t know if they even exist anymore or what names they are now using.
Hi Colin,
I need a bit of help.
I have a product image that requires web resizing for a client and they would like to the image to be at 72dpi.
When zoomed in 3 times, the image will appear slightly blurry, is there anyway around this?
Appreciate your reply!
Look at my tut on resolution too, https://photoshopcafe.com/understanding-image-resolution-photoshop-beginners/ 72 doesn’t mean anything on its own. Are the pixel dimensions tripling?
Hi
I want to convert JPG and PNG size to WEB size ( 250×300 and 728×90) How can i do this with PHOTOSHOP? I tried but i have problems. Thank you very much in advance
Save for web
Hi Colin, Thanks for this article. It sounds sensible but didn’t work with a pesky image I’m trying to downsize for the web . It is a kookaburra graphic in high res (from Adobe vector stock) that, when I try to reduce it from 3800 x 4000 odd px to 200 x 210 px, using bicubic sharper, looks like total rubbish. I blame Photoshop. Any thoughts on what might have changed or what I’m doing wrong would be most appreciated!
If its vector art, try a different resize setting, bicubic sharper prob isn’t best option. Also if its vector, you should scale it in illustrator
If I open a high resulation image in photoshop then automatically image become fad. Can you tell me any reason about this?
Thanks in advance.
Hi Colin, Thanks I’m a new subscriber to your channel. I am setting up files in Photoshop to send to the printer. Will the quality still be optimal if I send a 24 x 36 inch file to the printer and they print it to the much smaller 4 x 6″ size as well as the large print? It’s the same aspect ratio. Many Thanks
You might have to experiment. My guess is it will look better in PS because it does better interpolation (resizing) But maybe your print can do it well too, you would have to try both and see which looks best
Great article Colin. I am wondering how this compares to the new “Enhance” feature in Lightroom. Does LR simply have a streamlined and renamed version of the image resize feature in PS?
Obviously no matter how I submit it (1400 or 3000) the image will be displayed (on streaming sites etc) as the same size. So which approach would result in that final image being cleaner? jake
I doubt this is still active, but im testing something right now that a straight answer would speed up: Im creating cover art for music and the file submission requires 3000×3000 or 1400×1400. And the image im using is 4000X2250. So what would output a crisper clearer image: scaling the image up to fit 3000×3000 or scaling it down to fit 1400×1400.
Obviously no matter how I submit it (1400 or 3000) the image will be displayed (on streaming sites etc) as the same size. So which approach would result in that final image being cleaner?
its one of those things man.. plz help, jake
Scaling down is always better than scaling up
All great info. Pls explain more re: ur tip about resizing an image first using a graphic interpolation and then resizing the graphic version a second time using Biocubic smooth. Would you use preserve details on both? Is this the only “double play” that has value?
Also when would you increase ppi above 300?
If you need to boost it more, you might want to check out some of the 3rd party plugins for that
Nice tips.
What a grrrrreat site I stumbled over today‼️‼️ thank you.thank you.
My mom did beautiful paintings and now for her funeral I wanted to use a photo of one she signed, looking for a free 8bf, etc. To help me remove the signature on a photo of her painting. ……funeral is in two weeks. Pleassssssse.much deep thanks.✝️✝️😁😁
Great tips. Can this tips be same for logo? I have problem with logo resizing. When placing a logo on MS word Header and converting to pdf image quality and letters is poor. Kindly assist
Logos should be vectors whenever possible
COLIN!
I posted successfully here two days ago and my post is gone.
I would appreciate your help please.
If you removed it and now this one also, please tell me why.
You have such a wonderful site and I need the help please.
Merry Christmas!
What a grrrrreat site I stumbled over today‼️‼️ thank you.thank you.
My mom did beautiful paintings and now for her funeral I wanted to use a photo of one she signed, looking for a free 8bf, etc. To help me remove the signature on a photo of her painting. ……funeral is in two weeks. Pleassssssse.much deep thanks.✝️✝️😁😁
In order to keep spam off the site, I manually approve all posts. I just now approved your post, so it wasn’t deleted, it just didn’t show up yet. 🙂
Hi there
You can use Content aware fill, generative fill or the remove tool. I have posted lots of tuts on the site
This one will help: https://photoshopcafe.com/generative-fill-vs-remove-tool-ai-in-photoshop-when-to-use-each-tool/
‼️‼️‼️‼️‼️‼️‼️‼️‼️🔴🔴🔴🔴🔴🔴 COLIN PLEASE, i am down to days here.just been hanging on. I told everyone at the forthcoming funeral I am just waiting on your help……
Sorry for your loss
You can use Content aware fill, generative fill or the remove tool. I have posted lots of tuts on the site
This one will help: https://photoshopcafe.com/generative-fill-vs-remove-tool-ai-in-photoshop-when-to-use-each-tool/
When I open a high resolution image in photoshop then its automatically faded. Why its happening here?
Plz reply to me.
Advanced Thanks
Make sure your color profiles are set correctly
I was facing the problem of “Image resolution”. After reading your article i have got the best solution on it. Thanks for your very very informative article. Eagerly waiting for more.
So happy to help you
One thing rarely factored in is how the enlargement responds to various sharpening protocols. Bicubic Smoother can handle the most sharpening after the upsize and remains Adobes best general option to date. Lanczos (which Adobe does not have ) is similar but even better.
So, it’s not what looks the best on the surface, but how the result responds to sharpening.
Lastly, enlargements are viewed at 50% (print size). NOT 100%. 100 percent is 100% irrelevant for print.
And the high res displays are worse for evaluation. A pixel pitch of 100 is the best we can get today.
This is easily one of the most thorough resizing guides I’ve come acros, especially the part about interpolation and stair step. A quick suggestion.. if anyone’s dealing with images that don’t just need resizing but are also visibly corrupted (like weird color blocks, missing parts, or won’t open at all), resizing won’t help. I had a batch of travel photos that got damaged during transfer, and a desktop tool called stellar repair for photo actually fixed a bunch of them. It’s not for sharpening..its more for structurally repairing broken image files.